Actualités du catalogue nº 50 (décembre 2020)
à la Une : Une nouvelle version du portail API et jeux de données bientôt sur les écrans
Le portail api.bnf.fr, ouvert en novembre 2017 à l’occasion du deuxième hackathon BnF, décrit et documente l’ensemble des API (Application Programming Interface, interface de programmation applicative) qui permettent d’interroger et de récupérer les métadonnées des catalogues et les collections numérisées de la BnF. Pour faciliter l’accès aux données et leur utilisation, des jeux de données (images et textes, métadonnées, statistiques) ont également été constitués et sont directement téléchargeables via le portail. Chaque API ou jeu de données donne lieu à une présentation du contenu, une documentation technique, des précisions sur les droits d’utilisation et un accès aux données.
La version à venir bénéficiera d’une ergonomie repensée, avec des critères (sources de données, formats, sujets) destinés à faciliter la recherche des API et jeux de données, qui continuent de s’enrichir. Elle fera la part belle aux exemples de projets et de réutilisations des données de la BnF, comme ceux produits pendant les hackathons qui se sont déroulés à la BnF, avec la mise à disposition d’outils libres pour mieux utiliser ces données. L’accès aux jeux de données sera simplifié, et une console Swagger permettra de tester la plupart des API. Les données disponibles dans le portail sont exposées grâce à un flux de données structurées au format DCAT, ce qui permettra à d’autres portails de moissonner ces informations et d’en faciliter la diffusion.
L’enrichissement de ces services s’inscrit dans la stratégie d’ouverture des données affirmée depuis 2014 par la BnF avec l’adoption de la licence ouverte de l’État pour l’ensemble de ses métadonnées. Il s’agit d’en simplifier l’accès et d’en faciliter de nouveaux usages (alimentation de catalogues, création d’applications innovantes, fouille de données, datavisualisation, etc.) auprès de publics professionnels diversifiés (développeurs, entrepreneurs, acteurs de la culture et de la chaîne du livre, chercheurs) ou tout simplement des amateurs de culture. Cette stratégie se poursuit avec l’ouverture prochaine, en partenariat avec la très grande infrastructure de recherche du CNRS Huma-Num, du BnF DataLab, un laboratoire consacré aux humanités numériques au sein de la BnF.
Focus sur data.bnf.fr et ses évolutions
Les ambitions de data.bnf.fr sont toujours les mêmes depuis son lancement en 2011 :
- rendre interopérables et accessibles sur le web les données de la BnF provenant des différents catalogues et ressources de l’établissement (BnF catalogue général, BnF archives et manuscrits, Gallica, etc.) ;
- montrer en quoi le modèle IFLA LRM peut bénéficier à nos usagers ;
- être une plateforme d’expérimentation autour de la LRMisation des catalogues de bibliothèque.
L’interface, organisée autour des entités décrites dans le modèle IFLA LRM, offre de nouvelles possibilités de navigation dans les données de la BnF. En outre, le site rend accessibles ses données via un SPARQL Endpoint (outil de requêtage) et des dumps (exports) permettant à l’internaute de les récupérer en RDF pour les consulter et les manipuler plus librement. Ces données sont diffusées sous la licence ouverte de l’État. Pour maximiser la réutilisation par des communautés larges, les ontologies privilégiées sont celles communément utilisées par le web sémantique. De plus, des liens supplémentaires sont calculés automatiquement entre les données de la BnF et les données externes (Idref, Wikidata, etc.).
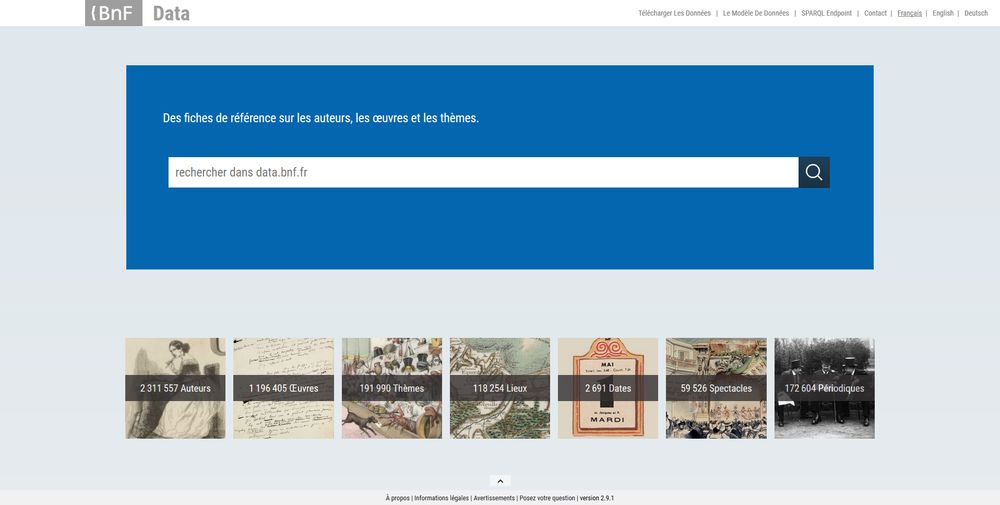
Un jalon important a été franchi en 2019, avec la mise en ligne d’une nouvelle interface. Le modèle des fiches (auteur, œuvre, thème, lieu, périodique et spectacle) a été conservé, mais l’ergonomie et le graphisme des pages ont été repensés pour en rendre l’abord plus aisé. Parallèlement, un outil de génération automatique d’œuvres (RobotDonnées) a permis d’aller plus avant dans le processus de LRMisation des données bibliographiques en créant plus d’un million d’œuvres par la mise au point d’un algorithme de calcul automatique.
Les prochaines années s’annoncent riches en évolutions. La réflexion sur les orientations du site pour les quatre prochaines années s’articule autour de quatre grands axes :
- Optimiser l’existant : continuer à développer et à améliorer le site et les données sous-jacentes.
- Permettre l’accroissement des données : augmenter le nombre des alignements et l’enrichissement des données.
- Accompagner la Transition bibliographique : travailler sur l’interface pour préfigurer les catalogues de demain.
- Faire émerger de nouveaux usages : consolider les liens avec les utilisateurs pour une meilleure prise en compte de leurs besoins et en identifier de nouveaux.
Le projet data.bnf.fr s’adresse tout autant au grand public qu’aux professionnels des bibliothèques, et vos remarques et suggestions sont toujours les bienvenues à l’adresse data@bnf.fr
Veille catalogue : Restructurer des zones de titre pour mieux identifier les œuvres
| Ancienne zone 245 | Nouvelle zone 245 |
|---|---|
| $a L’Eternelle comédie, par Germaine Briffault… [Préface d’André Foulon de Vaulx] $d Texte imprimé | $a L’Eternelle comédie $d Texte imprimé $f par Germaine Briffault… $g [Préface d’André Foulon de Vaulx] |
| Ancienne zone 245 | Nouvelle zone 245 |
|---|---|
| $a Université de Rennes. Faculté de droit. Thèse pour le doctorat. Des Attributions du Conseil d’État en matière législative et réglementaire… Thèse… par Joseph Franco,… $d Texte imprimé |
$a Des Attributions du Conseil d’État en matière législative et réglementaire… $d Texte imprimé $f Thèse… par Joseph Franco,… $g Université de Rennes. Faculté de droit. Thèse pour le doctorat |
Ces deux chantiers concourent à l’évolution progressive du Catalogue général vers le modèle IFLA LRM. Aujourd’hui, la zone de titre dans certaines notices n’est pas conforme aux normes de catalogage en vigueur et ne permet pas d’identifier les similitudes avec les titres d’autres notices, empêchant ainsi leur regroupement sous forme d’œuvre. La meilleure identification des œuvres constitue une étape essentielle dans le processus de LRMisation du Catalogue général.
Trois questions à… Philippe Goguely, chargé d’études documentaires

Quel était l’objectif de votre mission et comment avez-vous procédé ?
Ma mission consistait à proposer des traitements automatiques ou semi-automatiques pour injecter dans les pages d’œuvres de data.bnf.fr des liens vers les versions numérisées présentes dans Gallica quand ces liens n’existent pas dans les notices de BnF catalogue général. L’objectif est d’améliorer les services de la BnF aux lecteurs en leur donnant accès aux versions numérisées de toutes les œuvres référencées dans data.bnf.fr. Pour ce faire deux actions principales ont été identifiées : déterminer un corpus d’œuvres pour lesquelles une version numérisée « de (p)référence » serait mise en avant sur les pages de data.bnf.fr, sur la base de sélections manuelles ; et utiliser des tables des matières numérisées en XML dans Gallica, qui permettent, par exemple, de révéler que Le bal de Sceaux de Balzac, apparemment non numérisé selon data.bnf.fr et selon BnF catalogue général, est en réalité présent dans le tome 1 de l’édition en 20 volumes des Œuvres complètes de cet auteur, paru en 1853, aux pages 91-144.
J’ai procédé en deux temps. À partir d’un corpus d’une dizaine d’auteurs choisis parmi les Essentiels de la littérature, j’ai commencé par m’assurer que la liste de leurs œuvres référencées dans data.bnf.fr était exhaustive, en comparant celle-ci avec celle fournie par Wikipédia ; puis j’ai vérifié si chaque œuvre était bien reliée à une version numérisée dans Gallica. Techniquement, cela consiste à s’assurer que chaque notice de « Manifestation » numérisée contient un lien vers la notice « Œuvre » correspondante. Pour mener à bien cette mission, j’ai effectué des requêtes SPARQL (Protocol and RDF Query Language) dans data.bnf.fr. J’ai ensuite proposé des traitements automatiques pour créer des liens entre l’œuvre dans data.bnf.fr et les notices des manifestations numérisées dans Gallica.
Quel est l’intérêt des requêtes SPARQL par rapport à d’autres modalités de récupération comme l’export en CSV depuis l’interface publique de BnF catalogue général ou le SRU ?
Un SPARQL Endpoint est une interface de recherche pour interroger une base de données RDF en utilisant un langage de requête spécifique appelé SPARQL. Cette interface peut être utilisée par un utilisateur ou par un programme informatique pour extraire des données de la base. C’est un outil puissant pour interroger des corpus conséquents, « faire parler » les identifiants ARK et obtenir des liens qu’on exporte ensuite en format CSV.
Le service data.bnf.fr joue un rôle de pivot documentaire articulant différentes données numériques et descriptives provenant de bases internes comme externes à la BnF (BnF catalogue général, Gallica, BnF archives et manuscrits, Wikidata, VIAF, etc.). Ces données sont exprimées en RDF selon les standards du web sémantique qui repose sur le principe des relations entre les données.
Le SPARQL Endpoint de data.bnf.fr permet de chercher les relations sur un jeu de données identifiées par des ARK. En fonction des requêtes effectuées, j’ai pu obtenir des statistiques pour une première approche, puis extraire des données pour les analyser et proposer des solutions de traitements automatiques (voir exemples de requêtes). C’est un outil complexe qui requiert des compétences en web de données et en syntaxe RDF et demande à être très précis et rigoureux dans la syntaxe des requêtes. Il demande également une bonne connaissance du modèle de données de data.bnf.fr mais lorsque l’on est familiarisé avec cet outil, son usage devient passionnant. Les identifiants pérennes utilisés par la BnF, ARK et ISNI, m’ont été très utiles.
En quoi les identifiants pérennes ARK et ISNI vous ont-ils été utiles ?
L’ISNI est un identifiant international utilisé par de nombreuses bases de données sur le web, dont Wikipédia et BnF catalogue général qui alimente data.bnf.fr. Il est un moyen simple et efficace pour identifier un auteur de façon non ambiguë, et distinguer par exemple Alexandre Dumas père du fils. Pour avoir une liste de référence des œuvres de chaque auteur, j’ai commencé mes recherches en partant des pages auteurs de data.bnf.fr sur lesquelles l’ISNI attribué est indiqué, cela m’a permis de récupérer toutes les manifestations numérisées liées à un auteur. Cet identifiant est bien mis en évidence sur les pages de data.bnf.fr et son utilisation est donc évidente.
Les ARK sont utiles lorsqu’on récupère les résultats pour utiliser des liens pérennes vers une ressource précise, décrite par la BnF. C’est un format d’identifiant adopté par la BnF pour toutes les ressources qu’elle crée ou conserve (notices, documents numérisés ou nativement numériques, ressources pédagogiques, etc.). Il permet de lier, de référencer, d’aligner les ressources de la BnF entre elles et avec les ressources de silos de données extérieurs (comme la galaxie des outils Wiki, et notamment Wikidata).
Le saviez-vous ? La BnF et l’Abes coopérent au service de la qualité et de la complétude des métadonnées
La BnF met à disposition de l’Abes une extraction mensuelle au format KBART contenant différentes métadonnées relatives aux périodiques numérisés dans Gallica (titre de la publication, ISSN de l’original imprimé, ISSN de la reproduction numérique, date de parution et numéro de la première et de la dernière livraison disponible en ligne, etc.). Le fichier produit alimente BACON, base de connaissance nationale administrée par l’Abes. Cet entrepôt de métadonnées de référence sous licence CC0 a pour but de signaler les ressources électroniques, d’en faciliter l’accès et de favoriser le partage des données collectées. L’Abes fournit en retour à la BnF un diagnostic de qualité qui met en évidence l’absence de certaines données (en particulier l’ISSN des reproductions numériques) ou certaines incohérences de dates (par exemple, lorsque la date de la première livraison disponible en ligne est antérieure à la date de début du périodique imprimé). Ce rapport d’anomalies est désormais exploité systématiquement par le Centre ISSN France qui attribue des identifiants aux reproductions numériques et surtout par le pôle de catalogage du département de la Conservation qui vérifie les écarts de dates, déplace et/ou corrige des unités de conservation numérique, crée le cas échéant des parties d’exemplaires numériques sous les « bonnes » notices de périodiques, etc.

Ainsi s’est créé entre les deux agences bibliographiques un cercle vertueux bénéficiant à la fois aux acteurs de la communication scientifique qui ont recours à BACON et aux utilisateurs de Gallica ou du Catalogue général de la BnF.
Signalement de ressources
Chantiers et retours d’expériences de bibliothèques sur la transformation des catalogues vers une structuration selon le modèle IFLA LRM
Le programme Transition bibliographique incite les bibliothèques françaises à mettre leurs catalogues en conformité avec le modèle conceptuel IFLA LRM qui permet de s’extraire de la logique de document pour fournir une information plus large sur des données telles que les personnes, les œuvres, les événements, etc. Dans ce contexte, le groupe Systèmes & Données propose un tour d’horizon d’expérimentations et de chantiers engagés par plusieurs bibliothèques.
Rencontres
5e journée professionnelle du groupe Systèmes & Données de la Transition bibliographique (4 décembre 2020)
Cette journée, placée sous le thème « Cataloguer par entités ou le big bang des données », aborde en trois temps la notion de catalogage par entités : à travers une explication du concept, la présentation des outils nécessaires et quelques chantiers ou réalisations en cours. En savoir plus.
Webinaire à destination du réseau Rameau et des formateurs (12 janvier 2021)
Ce webinaire, organisé par le Centre national Rameau, sera consacré aux principales évolutions apportées au langage dans le cadre de la réforme de Rameau. Les questions de récupération de données et l’avancée du groupe national normatif de la Transition bibliographique Concepts-Lieux-Temps y seront également évoquées. Inscription en ligne.
Publications
Recommandations pour l’échange de données d’exemplaire en UNIMARC
Les recommandations sur la description des données d’exemplaire en UNIMARC, utilisées dans le cadre des échanges bibliographiques régionaux et nationaux, publiées pour la première fois en 1998, ont fait l’objet d’une révision. Consulter ces recommandations dans la version mise à jour en septembre 2020.
En chiffres
Au cours de l’année 2020, plusieurs bibliothèques partenaires du dispositif Gallica marque blanche ont procédé au chargement dans le Catalogue général de la BnF de notices bibliographiques et d’autorité :
- Bibliothèque municipale de Deauville : 1 444 notices bibliographiques, 135 notices d’autorité Personnes ;
- Bibliothèque municipale du Havre : 10 812 notices bibliographiques, 61 notices d’autorité Personnes ;
- École nationale des ponts et chaussées : 4 166 notices bibliographiques, 94 notices d’autorité Personnes.
En savoir plus sur la lettre d’information Actualités du catalogue
